AWS-急造環境でもチープなりに冗長性を考えるの巻
長く使われると継続性が問われちゃう罠
また緊急事態宣言に蔓防なわけで状況はまだまだ続くようです。
そもそもまあ、無いよりマシで停まったら停まったで諦めろという前提だったのに使い続けれると停まりっぱだと困ると言われるようになるのは世の流れ・・・
一時凌ぎ環境でも利用され続けれると内容しょっぱくてもシステムは育ってしまうというのを学びました。
そんなこんなでコンプライアンス周りもですが実際は転職しちゃったので残った人たちに対処方針だけは託しました。
振り返るとずいぶん前の東京リージョンのAZ障害の時に前日バックアップから別AZへのリストアで対処して以降は運よくクラウド障害に巻き込まれず退職するまで元気に動いておりました。
とはいえ本気で運が良かっただけだです。トラブった時に気付けば対処できるように複数AZにサブネットを配置していてもRDSとEC2は金ケチって単一AZで動いているので人いないとアウトな作りなです。
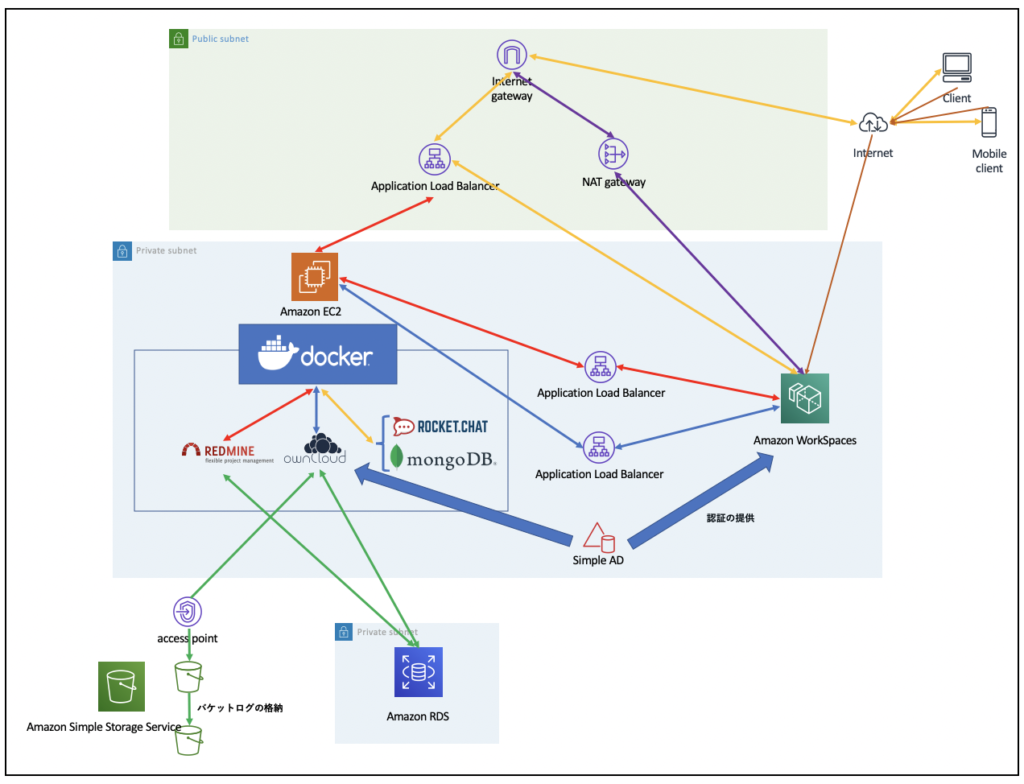
ということで自然と障害があっても自動的に継続する仕組みでを結局なるべく安く、簡単に作る方法を考えるわけです。
RDSはコスト増にはなるもののバックアップからマルチAZ構成にすれば良いので対処はお手軽ですが、Web+APが問題。
コンテナを利用しているのでECS+Fargateという選択がコスト的にもほんとはベストなんでしょうけど根本的に見直しが必要で簡単というわけにはいかないのです。
EC2だし素直にAutoScalingで対応しよう
なので、素直にAutoScaling機能使ってAutoHealingするのが簡単という結論になります。
EC2に必要なデータは永続領域を設定していてもローカルで動作するDockerコンテナなのでそのままAutoHealingしても
意味がないのでデータ領域を外出しにしてEC2は純粋にコンテナだけ動かすような形にする必要があります。
構成としては下図のようなイメージです。
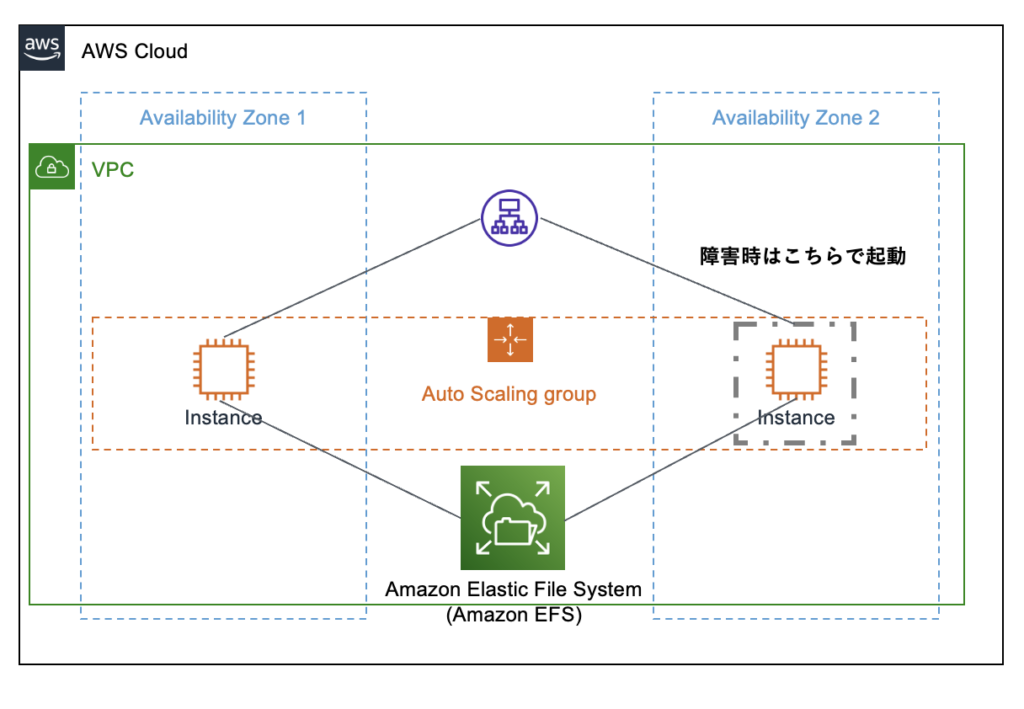
コンテナのデータ格納部分Amazon EFSに格納すれば対応できるし、コンテナイメージは変更時に別にバックアップしてるし将来的にFargate+ECSとかに移行しやすそうかなと。
Amazon Elastic File System(EFS)の作成とデータ移行
まずはEFSを作成しないと始まりません。
Amazon EFSをメニューから選択してダッシュボードからファイルシステムの作成を選択します。
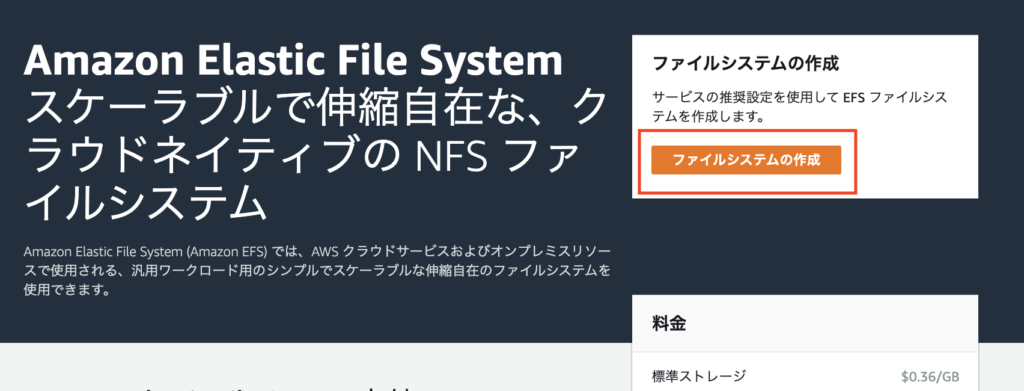
ファイルシステムの作成ウィンドが開くので、以下のように選択
- 名前:ファイルシステムの名前です。わかりやすい名前をつけましょう
- 1Vortual Provate Cloud(VPC):EFSを利用するEC2が配置されているVPCをプルダウンから選択
- 可用性と耐久性:AZ障害時の対応目的なのでリージョンを選択
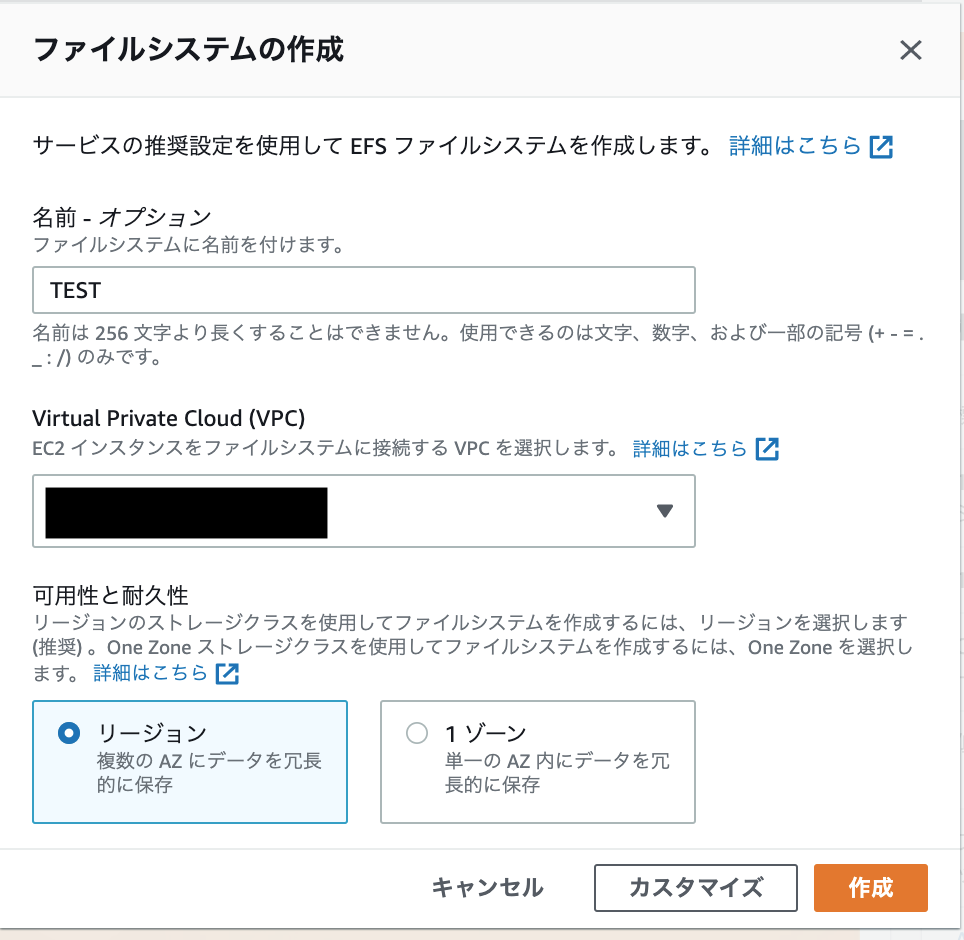
最後に「作成」をクリックします。
作成されたファイルシステムのリンクをクリックし詳細の画面に移動します。
移動後、画面右上の「アタッチ」をクリックします。
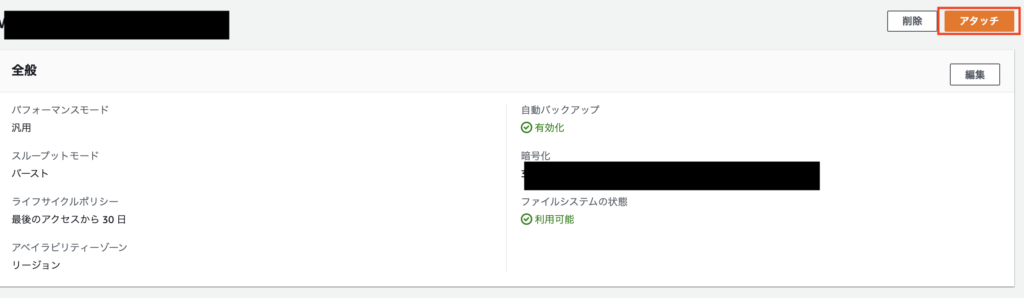
マウントのためのコマンドが表示されるのでどこかに控えて起きます。
お手軽に設定したいので、DNS経由でマウントのEFSマウントヘルパーの使用部分をどこかにコピーしておきます。
ファイルシステムの詳細には他にも容量情報以外にいろいろ設定できる項目もありますが、とりあえず凝ったことはしませんがセキュリティグループだけは設定しておきます。
詳細画面のタブメニューからネットワークを選択します。

画面移動後、右側にある「管理」をクリックし、マウントターゲットを設定します。
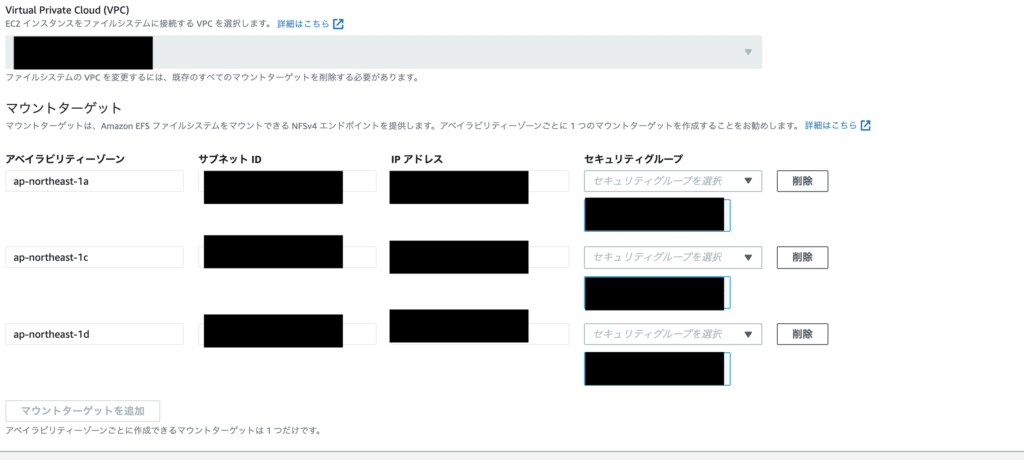
VPCはファイルシステムの設定時に選択され、配下のAZ、サブネットID、IPアドレスが設定されています。
サブネットを複数に分割している場合は一旦不要なマウントターゲットは削除ボタンをクリックして削除し、マウントターゲットの追加でAZ、サブネットIDを選択してください。IPアドレスは自動で付与されます。
セキュリティグループは初期ではdefaultが選択されているので不要であれば削除して、設定したいセキュリティグループをプルダウンから選択します。
セキュリティグループはNFSの通信許可が必要になりますが、同じSGが適用されていれば相互通信可能の設定が入っていれば個別にNFSを許可する必要はないです。
EFSの仕込みはこれで完了です。
EC2上のデータのお引っ越し
EFSにEC2の必要なデータを引っ越しします。
EC2にログインして、マウント先ディレクトリを作成してあらかじめ控えておいたコマンドでマウントします。
マウントの前にEFSクライアントがインストールされているか確認します。
$ sudo rpm -qi amazon-efs-utils Name : amazon-efs-utils Version : 1.31.2 Release : 1.amzn2 Architecture: noarch Install Date: Wed 07 Jul 2021 01:24:36 AM UTC Group : Amazon/Tools Size : 174417 License : MIT Signature : RSA/SHA256, Mon 28 Jun 2021 08:12:59 PM UTC, Key ID 11cf1f95c87f5b1a Source RPM : amazon-efs-utils-1.31.2-1.amzn2.src.rpm Build Date : Thu 17 Jun 2021 05:34:10 AM UTC Build Host : build.amazon.com Relocations : (not relocatable) Packager : Amazon.com, Inc. <http://aws.amazon.com> Vendor : Amazon.com URL : https://aws.amazon.com/efs Summary : This package provides utilities for simplifying the use of EFS file systems Description : This package provides utilities for simplifying the use of EFS file systems
インストールされていなければ、以下でインストールします。
$ sudo yum install -y amazon-efs-utils
インストールしたら、ディレクトリを作成してマウントします。ディレクトリはお好みの名前でどうぞ。
$ sudo mkdir /efs $ sudo mount -t efs -o tls 【ファイルシステムID】:/ efs
正常にマウントしていれば、dfコマンドで確認するとESFのマウントが以下のように確認できます。
$ df 〜中略〜 【ファイルシステムID】.efs.【リージョン】.amazonaws.com:/ 9007199254739968 1805312 9007199252934656 1% /efs 〜以下、略〜
移行するコンテナを停止してから、永続ボリュームを引っ越します。私は念の為、アーカイブしてからコピーしました。
$ cd /volume $ sudo tar czv rocket_chat.tar.gz ./rocket_caht $ sudo cp -pri ./rocket_chat /efs/.
正体はNFSなんでストレージとしては遅いです。データがでかいとそこそこ時間がかかります。
また、EFSは利用する容量に対して課金されます。標準ストレージでGBあたり0.36USD/月です。EBSと比べたらGBあたりの単価はベラボーに高いのでご注意ください。
性能面はプロビジョンでスループットを指定して性能を安定させることもできますが内部利用とか限定利用とかの仕組みならとりあえずバーストモードでしばらく様子見てからで良いと思います。
とりあえずテスト起動してみる
データの引っ越しが終われば、EFS側ボリュームにコピーしたdocker-compose.ymlを修正します。
修正といっても、volumesの部分を必要に応じてEFSのマウントポイントからのパスに変更するだけです。
以下のように指定している場合は修正は不要です。
volumes:
- ./uploads:/app/uploads
volumes:
- ./data/db:/data/db
念の為オリジナルのディレクトリはアーカイブして削除してからEFS上のディレクトリ配下に移動してdocker-compose startで起動できればOKです。
今までと同様にアクセスできるかブラウザ上から確認してください。
正直、「うーん、ちょっともっさり・・・」とか思うかもしれませんがトレードオフですので割り切って当面気にしないでおきましょう。
自動マウントの設定入れとこう
動くのを確認したら当然のごとく起動時にマウントするように設定しないと意味がありますまい!
/etc/fstabにEFSボリューム用の設定を追加します。以下のようにfstabの末尾に追加します。
【EFSボリュームID】:/ /efs efs defaults,_netdev 0 0
一度、docker-compose stopでコンテナを停止してからEC2を再起動して正常にマウントされdfで認識されていること、コンテナが起動することを確認します。
AutoScalingを設定
AutoScalingの設定の順番
AutoScalingの設定は以下の順番で行います。
- EC2のAMI作成
- 起動設定
- AutoScalingグループの設定
EC2のAMI作成
AutoScalingは特定の条件時に自動的にEC2を作成する仕組みなのでその元となるイメージをAMIとして作成しておく必要があります。
EFSの自動起動まで終了したEC2を念の為に停止してEC2インスタンスのアクションからイメージを作成を行います。

イメージ名と説明にはAutoScalingで利用していることがわかるようにわかりやすい名前をつけます。
基本的には他は何も弄らずAMIを作成します。
EC2サービスのAMIに指定した名前で作成されステータスがavailableになっていれば完了です。
起動設定
AMIが作成できたらEC2サービスのAutoScalingから起動設定を選択します。
起動設定の作成をクリックし以下の起動設定を行います。
| 項目 | 設定内容 |
| 名前 | 起動設定名です。わかりやすい名前で設定しましょう |
| Amazon マシンイメージ | 「1.EC2のAMI作成」で作成したAMIをプルダウンから選択します。ami-idを直接入力してもOKです |
| インスタンスタイプ | 起動時に利用したインスタンスタイプを設定します |
| 追加設定 | IAMインスタンスプロファイルにEC2に指定したいIAMロールを設定する以外は今回は何もしません。 実際はユーザデータなども設定もここで設定できます |
| ストレージボリューム | 今回は何も設定しません |
| セキュリティグループ | 既存のセキュリティグループを選択すると設定済のリストが表示されるので、必要なセキュリティグループを選択します |
| キーペア | 既存のキーペアの選択で利用しているキーペアを選択します |
上記を設定したら起動設定の作成をクリックします。
AutoScalingグループの設定
続いてAutoScalingグループを設定します。
EC2サービスのメニューのAutoScalingからAuto Scalingグループを選択します。
Auto Scaling の作成をクリックします。
設定はステップ1ー5がありそれぞれ、設定して次へをクリックします。
ステップ1でまず、Auto Scalingグループの名前を入力します。わかりやすい名前を設定しましょう。
次に起動テンプレートですが今回は起動設定を利用するので、「起動設定に切り替える」をクリックします。
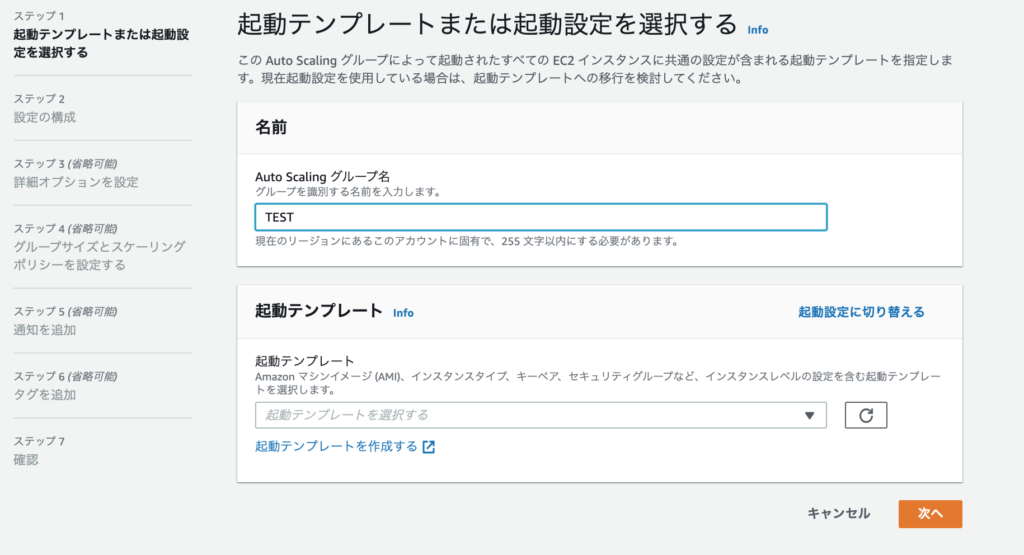
起動テンプレートが起動設定に切り替わります。
プルダウンから先ほど設定した起動設定を選択します。起動すると起動テンプレートの情報が表示されるので確認後「次へ」をクリックします。
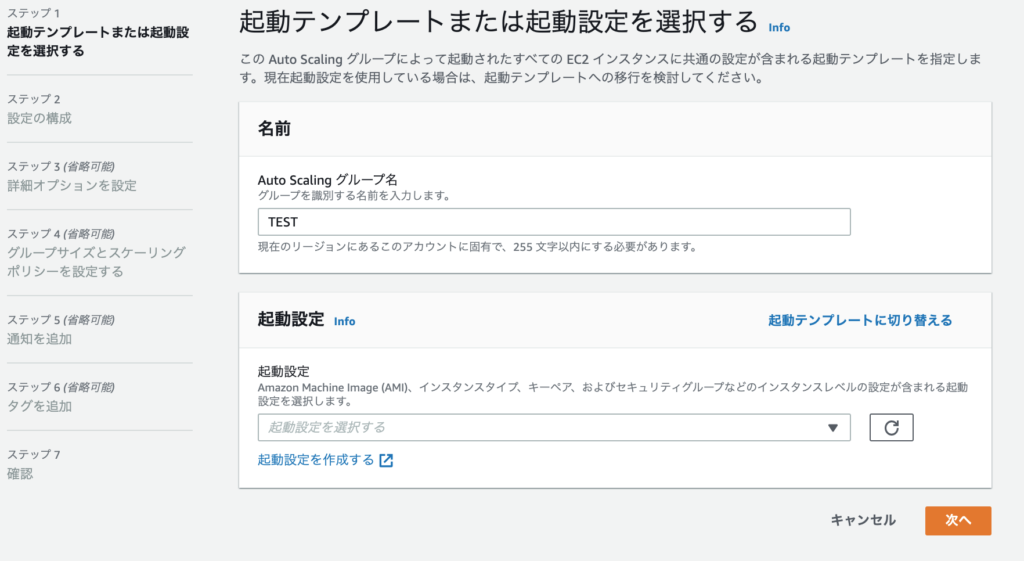
ステップではAutoScalingで利用するVPCとサブネットを設定します。
プルダウンから利用するVPCを選択し、サブネットも利用するサブネットを選択し追加します。
※以下はVPC内でAZ分のサブネットを登録しています。
選択後「次へ」をクリックします。
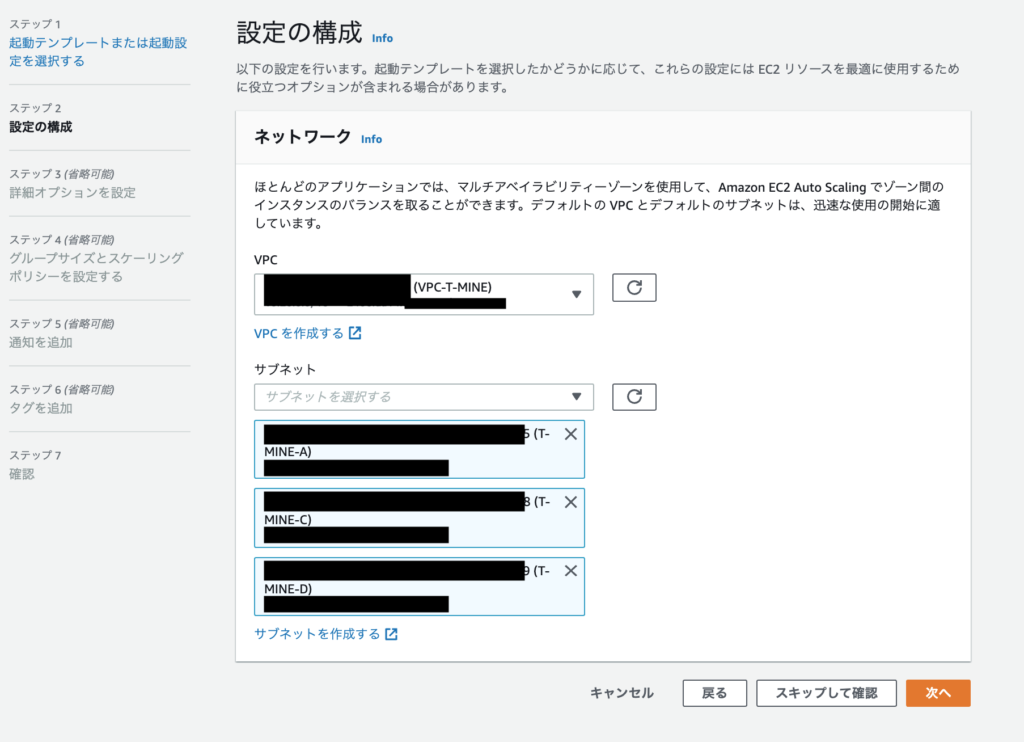
ステップ3ではロードバランサを利用するかの設定をします。
既存のロードバランサにアタッチを選択し、利用するロードバランサのターゲットグループをプルダウンから選択し追加します。
選択したターゲットグループにAutoScaling発動時に作成されたEC2が自動的に登録されるようになります。
ヘルスチェックに詳細にELBを追加すると、EC2のダウン時だけでなくELBからのヘルスチェックの異常時にもAutoScalingが動作します。
コンテナの異常時にも発動してくれますが、欲張るとロクなことがないのであくまでもEC2、AZ障害時の対応とするならELBのチェックはいらないと思います。
※RDSを利用していたりするならいいんですが、データベースもコンテナで動かしているような場合は迂闊にEC2が増えて排他制御あたりでデータベースがロックしたりしてアプリエラーになってEC2作成->削除の無限ループの原因になったりするのでご注意ください。
自分はやらかました。
ヘルスチェックの猶予期間はデフォルト300秒でがとりあえずこのままにしときます。
モニタリングもとりあえず省略します。
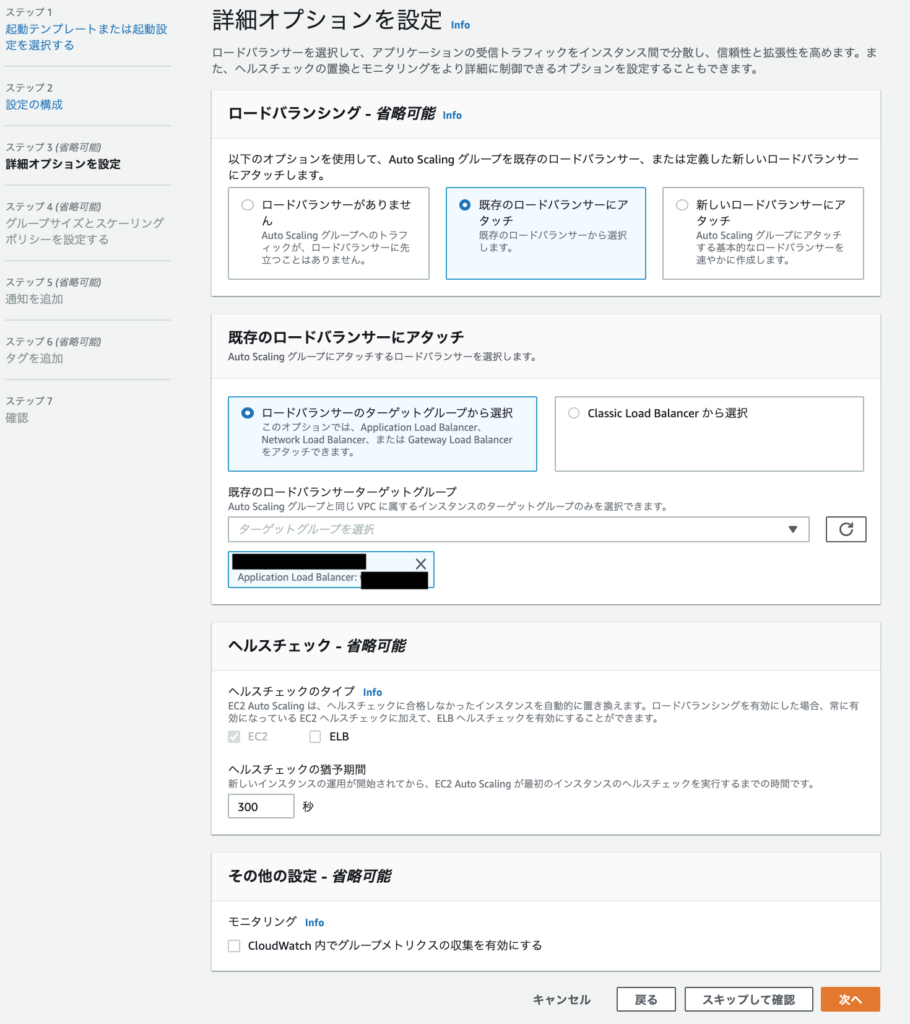
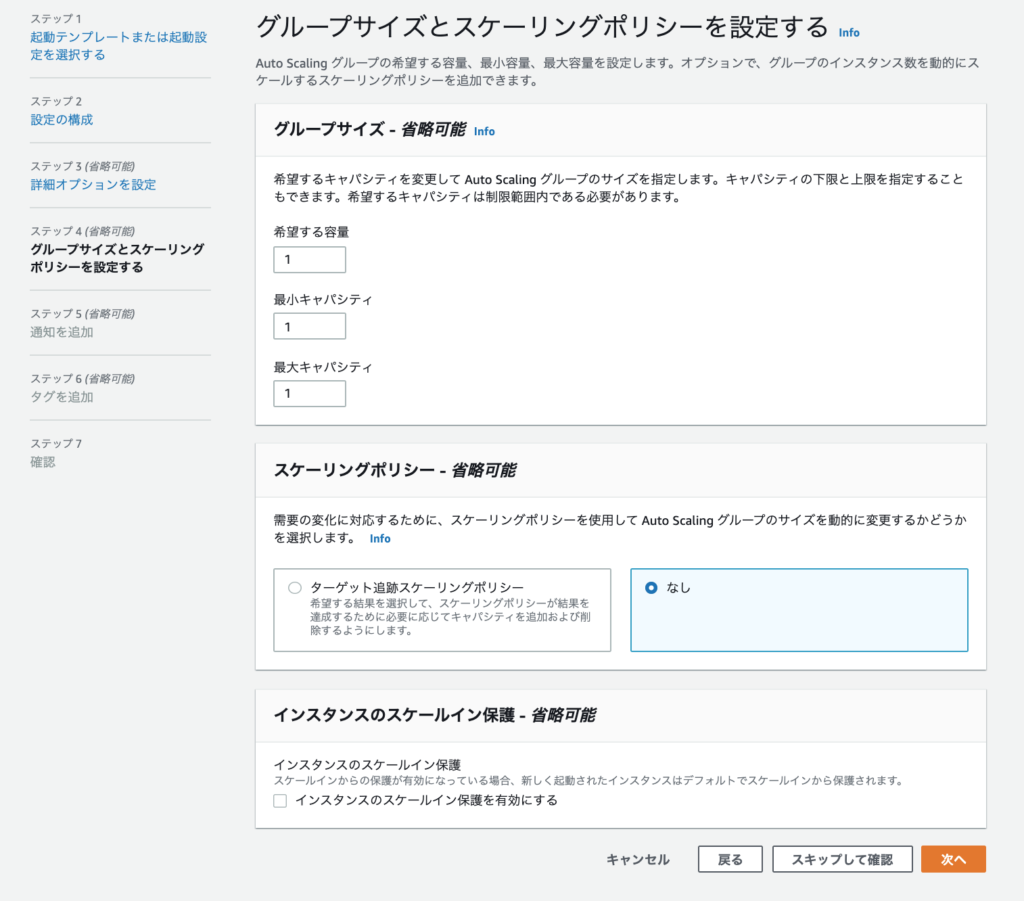
ステップ4で起動する台数を設定します。
グループサイズに希望する容量=最大と最低の間を入力しておくのが無難。振る舞いに影響します。
次に最小キャパシティ=最低限何台のEC2を稼働させるかの台数を入力します。
最後の最大キャパシティ=最大何台のEC2の稼働をさせるかの台数を入力します。
今回はあくまでもインスタンスの障害時に対応なので、EC2お一人様を前提にするので全て1にしておきます。
スケーリングポリシーもパフォーマンス応じてスケールを求めてないので「なし」のままにしておきます。
スケールイン保護に関してはいらないインスタンスは素直に削除されて欲しいのでチェックはつけないで「次へ」をクリックします。
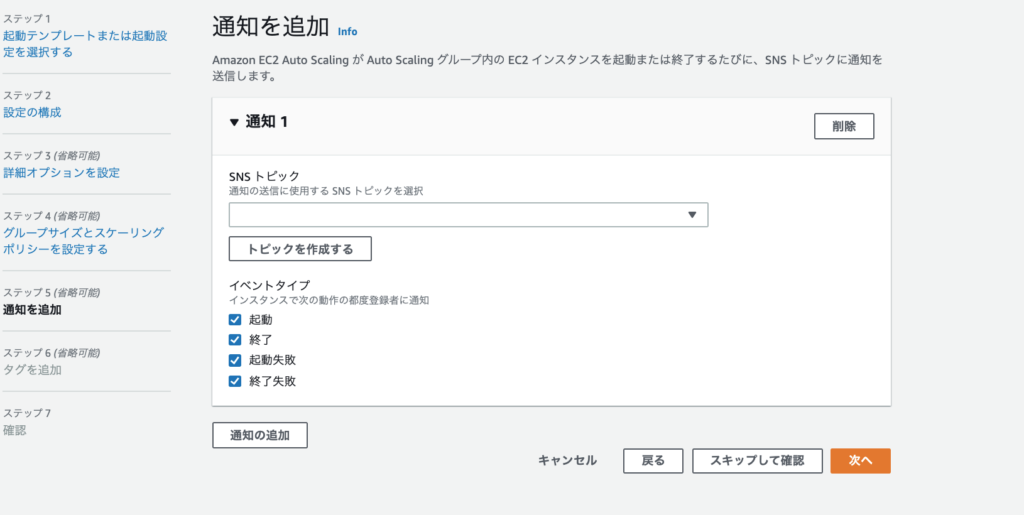
ステップ5は通知の設定になります。
AutoScaling発動時にはSNSで何かしらの通知は欲しいで、「通知の追加」をクリックすると以下のようにSNSトピックの選択と通知内容の選択になります。
イベントは全てチェックし、通知に使いたいSNSトピックをプルダウンから選択して「次へ」をクリックします。
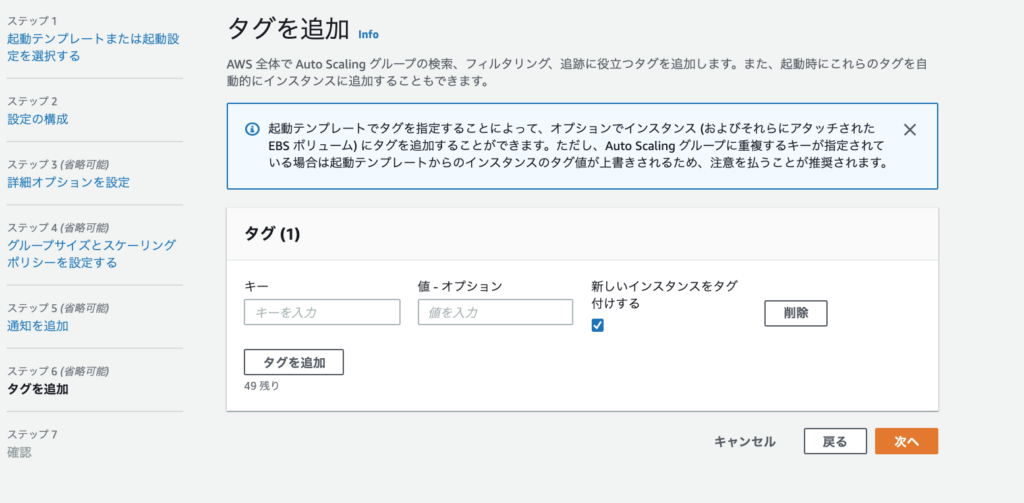
ステップ6はAutoScalingで作成されたリソースに付与するタグの設定になります。
特に設定しなくても良いですが、リソースが多い場合だとAutoScalingグループ毎に参加のリソースなどは知りたいと思うのでその場合はここで任意でタグを設定しておきます。
ステップ7で設定した内容の確認画面となるので、問題なければ「Auto Scalingグループの作成」をクリックします。
ここで作成された時点でポリシーに基づいてEC2のインスタンスが作成されます。
最後に手直しと注意点
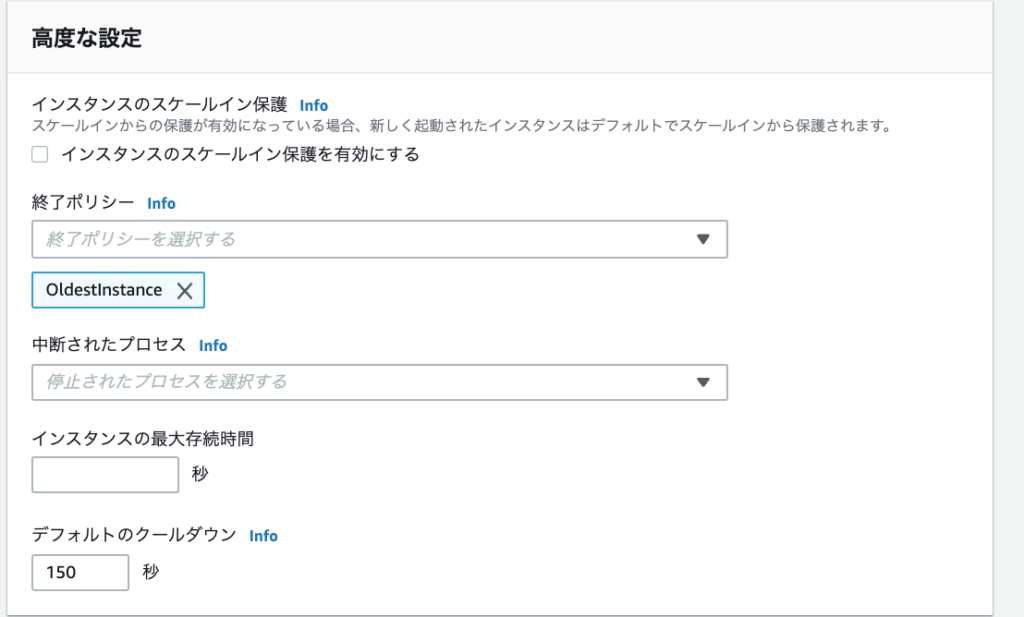
Auto Scalingのスケールイン時の削除ポリシーはデフォルトでは「OldestLaunchConfiguration」が選択されています。これは一番古いLaunch Configuretionのインスタンスが削除されるポリシーです。
動きとしてはまず一番古いものを消そうとし、複数ある場合には課金発生が短いものを消そうとします。
お一人様インスタンス相手なのでこれでも良いと言えば良いんですが、余計なことせずに古いものが削除されてくれる方が素直なのでポリシーを変更しておきます。
Auto Scalingグループのリストから作成したグループにチェックを入れ、編集をクリックします。
「高度な設定」の項目に終了ポリシーの選択があるのでデフォルトのものは削除し「OldestInstance」を選択します。
これで一番作成日が古いインスタンスを削除する動きになります。
またクールダウン(追加、削除の待ち時間)はデフォルトでは300秒ですが、とりあえずヘルスチェックの猶予期間の半分の時間で設定しておきました。
それと注意点ですが、設定のところでも書いた通りデータベースもコンテナでも起動するパターンの場合は重複でEC2が起動するとエラーになります。
クラスタとか考慮していないので壊れないように排他制御かかるので当然の動きではあるのですが手動で試しに稼働台数増やしたりとかするとEC2は増えたけど別のEC2でコンテナが起動中でブラウザから接続したらデータベースエラーになっているなんでことになっているのでご注意ください。
今回のケースはあくまでも、EC2障害かAZ障害した場合の対応でEC2は単一で起動するのが前提です。
手動なりでお試しする場合は事前にコンテナを停止するなりしてテストして見てください。